Menade inte i denna tråden utan i tråden som du länkade till för BulkLoadDemo. Har bildgooglat lite nu och av de få som inte kom från en intern icke-släppt version av Microsoft så hittade jag dessa:
https://ossan-gamer.net/wordpress/wp-content/uploads/2023/01/Pasted-86-445x300.jpg
https://ossan-gamer.net/wordpress/wp-content/uploads/2023/01/Pasted-86-1-500x293.jpg
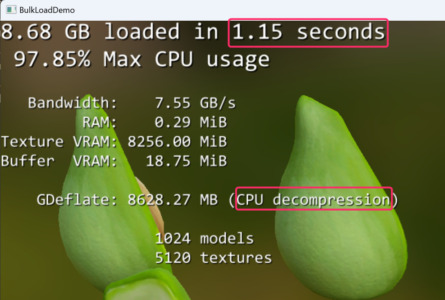
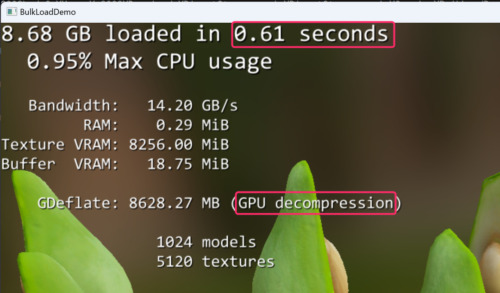
Så 88% förbättring, dock i praktiken 0,54s vilket knappt märks. Dock är det ju enbart på en liten avokado så vi får ju se hur det blir i verkliga spel med betydligt mer resurser om det skalar eller ej. Tyvärr framgår det ju inte heller av testen om fördelen här verkligen är att GPU:n är så pass mycket snabbare på deflate mot CPU:n eller om fördelen är att det är så pass mycket mindre data som måste kopieras från RAM till VRAM.
Ja då kanske du inte varit så aktiv i div trådar, forum och YT som en annan för det finns miljarder med människor där ute som är fast övertygade om att DirectStorage 1.2 skulle vara just att GPU:n kunde läsa direkt från NVMe, att då RTX4090, som varande nVidias flaggskepp på konsumentsidan, helt saknar P2P är ju en spik i den kistan. Dvs det där handlade enbart om att rätta till den missuppfattningen, inget annat.
Vinsten med det handlar då inte direkt om bandbredden över PCIe bussen utan mer om latensen över att först läsa in till RAM för att sedan kopiera till VRAM vilket t.ex konsoler som PS5 slipper, och att just PS5 slipper det är säkert också en källa till varför folk har missuppfattat detta.