

Visa signatur
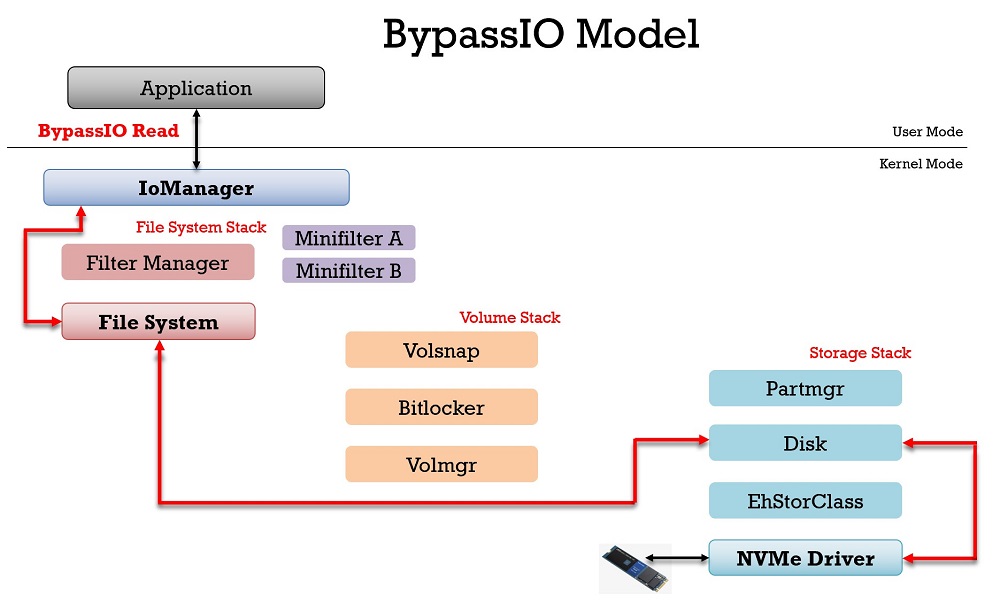
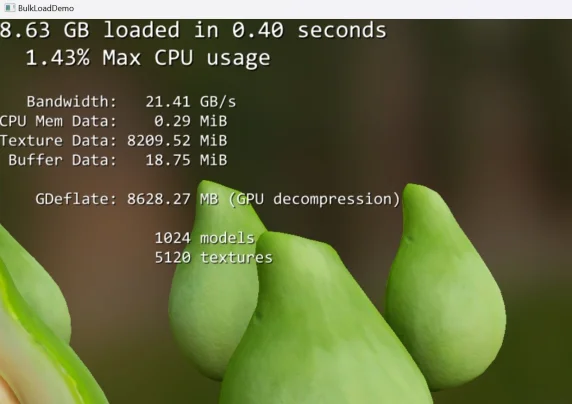
Nu kommer Nvidia RTX IO – snabbar upp laddtider


Visa signatur
Visa signatur

Visa signatur
5900X | 6700XT
Visa signatur

Senast redigerat

Visa signatur
5900X | 6700XT

Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer

Visa signatur
Ryzen 7 5800X3D | MSI B450 Gaming Plus Carbon AC | Adata XPG Spectrix D41 32GB 3600MHz CL17 | RX 6800 XT | SoundBlaster Z | Corsair 4000D + Seasonic FOCUS GX 750W | Samsung Odyssey G7
Hörlurar: Sennheiser HD650 + Millett Hybrid MiniMAX | Sony WF/WH-1000XM4 |
Visa signatur
5900X | 6700XT
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Visa signatur
5900X | 6700XT

Visa signatur
|Ryzen 5800x3d|RX 7900XTX Hellhound|Asus Prime X370 Pro|32GiB Corsair 2400MHz CL16 Vengeance|Corsair HX1000i|Fractal Define R5|LG 45GR95QE|Corsair K100|Razer DeathAdder V3 Pro|Ubuntu 23.10|
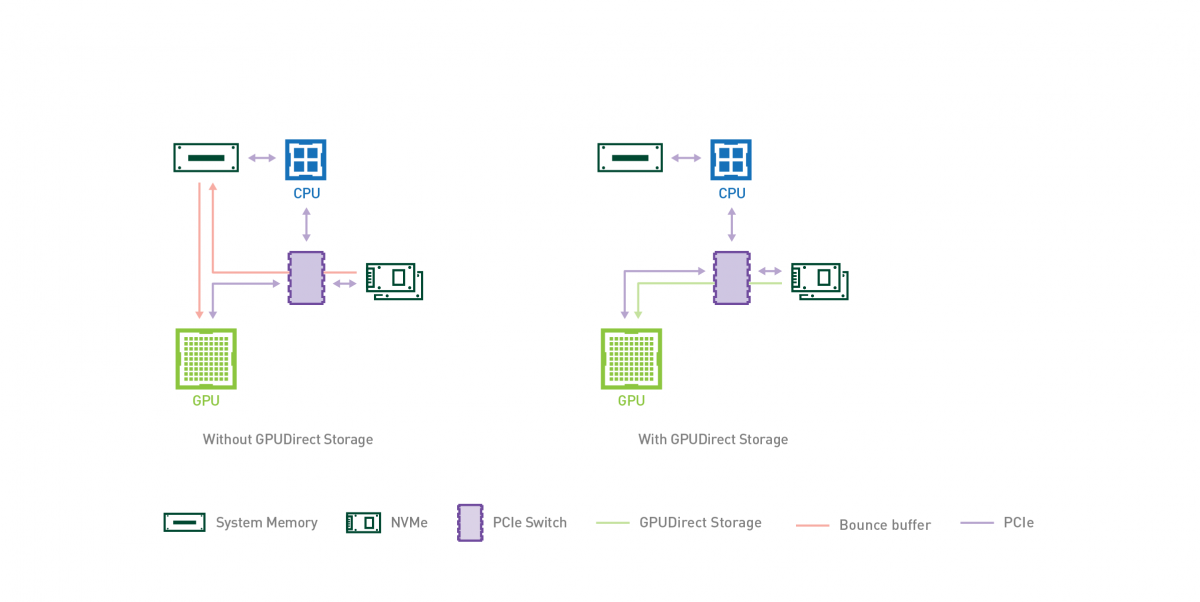
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Visa signatur
|Ryzen 5800x3d|RX 7900XTX Hellhound|Asus Prime X370 Pro|32GiB Corsair 2400MHz CL16 Vengeance|Corsair HX1000i|Fractal Define R5|LG 45GR95QE|Corsair K100|Razer DeathAdder V3 Pro|Ubuntu 23.10|
Visa signatur
Visa signatur
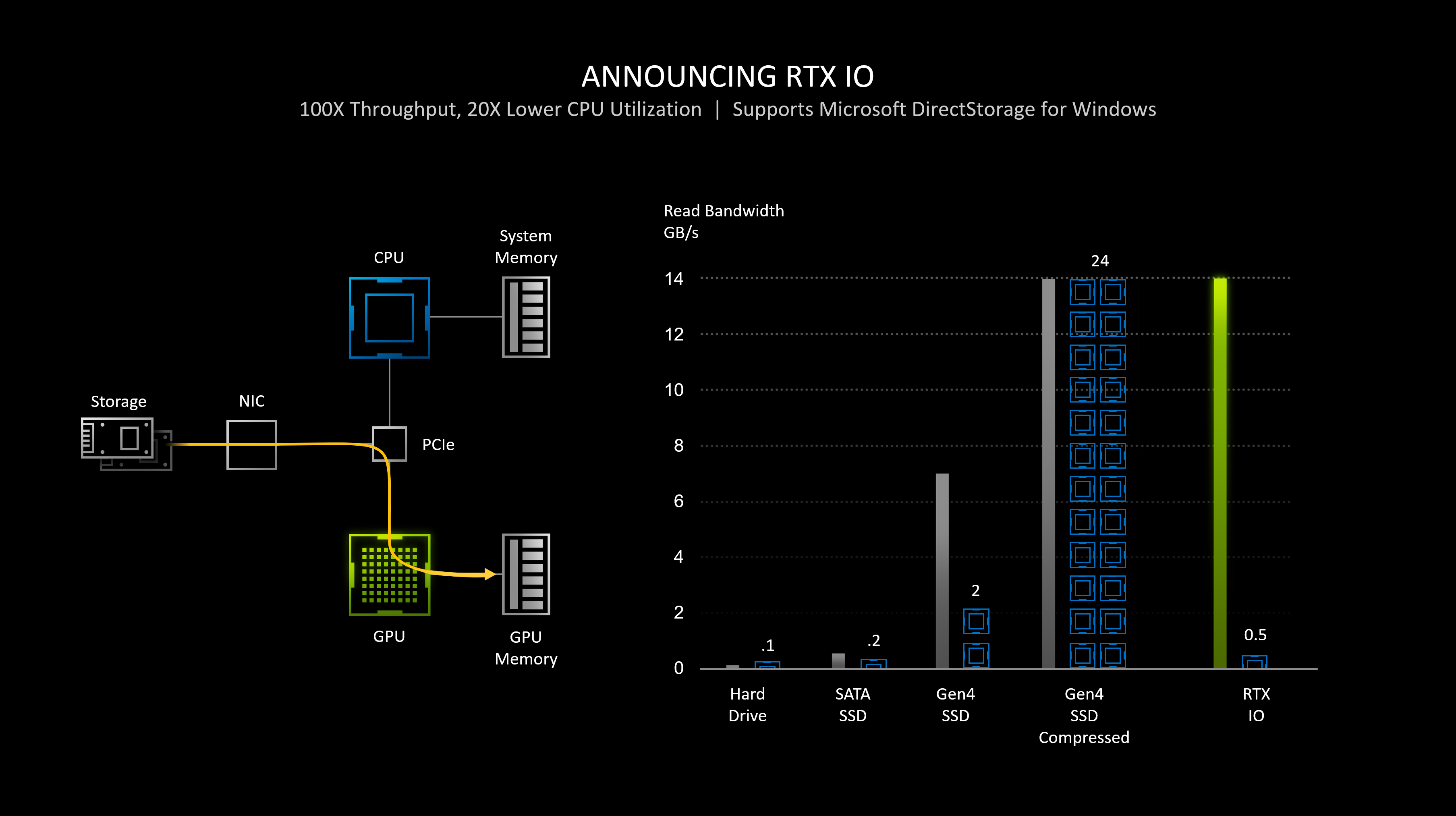
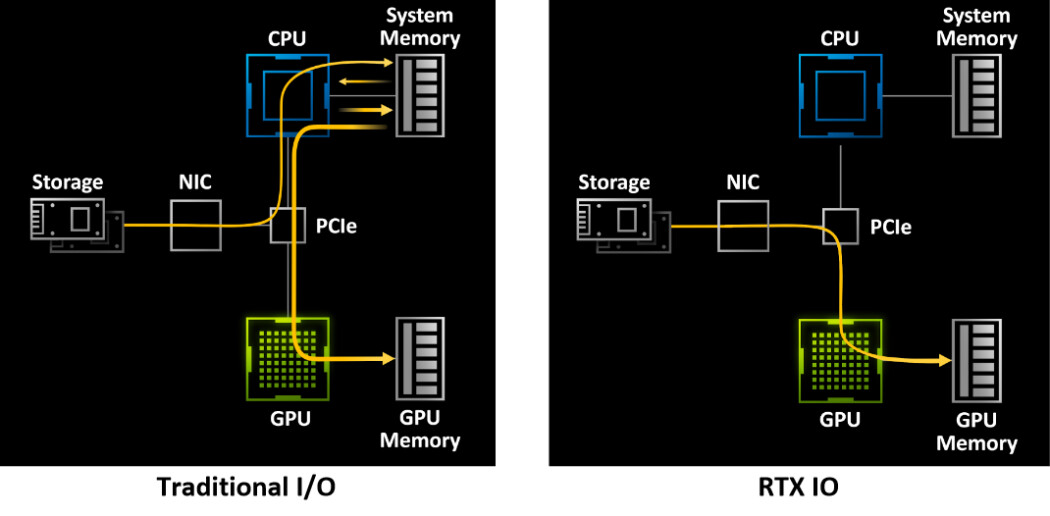
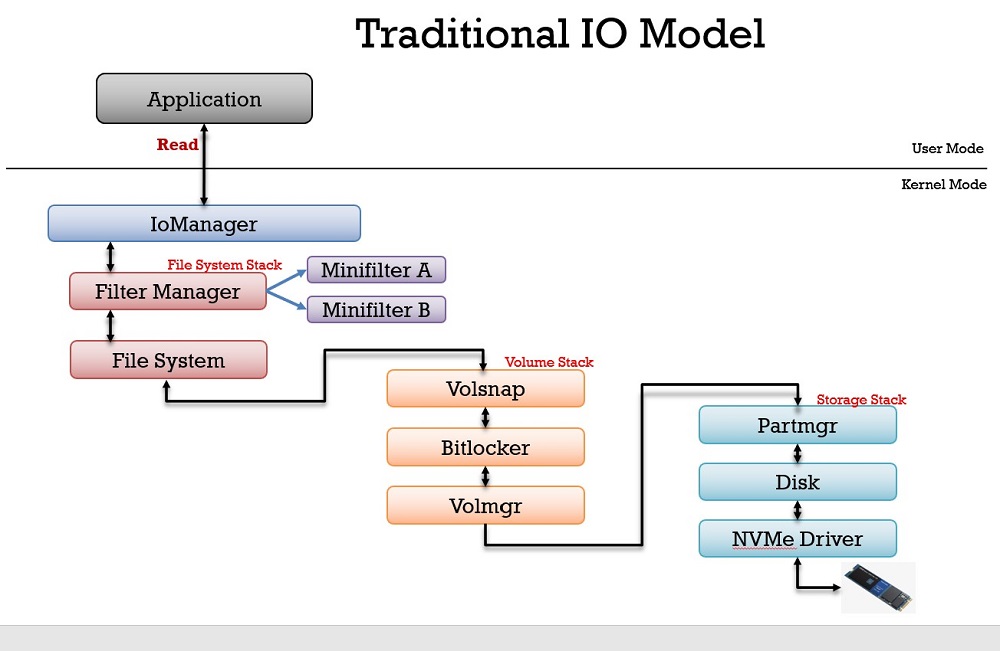
Visa signatur
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer
Visa signatur
Visa signatur
|Ryzen 5800x3d|RX 7900XTX Hellhound|Asus Prime X370 Pro|32GiB Corsair 2400MHz CL16 Vengeance|Corsair HX1000i|Fractal Define R5|LG 45GR95QE|Corsair K100|Razer DeathAdder V3 Pro|Ubuntu 23.10|
Visa signatur
Visa signatur
|Ryzen 5800x3d|RX 7900XTX Hellhound|Asus Prime X370 Pro|32GiB Corsair 2400MHz CL16 Vengeance|Corsair HX1000i|Fractal Define R5|LG 45GR95QE|Corsair K100|Razer DeathAdder V3 Pro|Ubuntu 23.10|
Senast redigerat
Visa signatur
Visa signatur
|Ryzen 5800x3d|RX 7900XTX Hellhound|Asus Prime X370 Pro|32GiB Corsair 2400MHz CL16 Vengeance|Corsair HX1000i|Fractal Define R5|LG 45GR95QE|Corsair K100|Razer DeathAdder V3 Pro|Ubuntu 23.10|
Senast redigerat
Visa signatur
