Skrivet av Aleshi:
Du förstår inte liknelser. Att något som är delat innan själva kärnan begränsar gör det inte mindre till en dualcore.
Så din definition är alltså: dual-core == 2 st separerade ALU/ALG enheter.
Men faller inte då modulerna på att ALU enheterna för FPU är delad? Och med delad här menar jag att det bara finns en schemaläggare för FPUn och jag är medveten att det är möjligt i vissa lägen att FPUn ändå klarar av att köra två 128-bitars instruktioner samma cykel. Men den är fortfarande delad vilket borde diskvalificera den som dual-core enligt dig.
Skrivet av Aleshi:
Nej, jag vet att den kan köra olika saker på olika exekveringsportar samtidigt. Men inget är dedikerat. Det är inte garanterat att en tråd kan få sin önskade exekveringsport då en annan tråd kanske redan använder den.
Men bulldozer delar ju back-end så det är möjligt att en instruktion inte kan färdigställas (retire) p.g.a. att den andra kärnan använder den resursen. Det ska alltså inte räknas, men en eventuell konflikt på en exekveringsport ska räknas?
Skrivet av Aleshi:
Precis, dedikerade resurser hela vägen här.
Nej, ganska osannolikt att det matchar särskilt bra. Du glömmer bort att intel kör heltal och flyttal på samma portar, en av AMDs 128bits FMAC kan exekvera 4 flyttalsoperationer också, med Flex FP där de kan låna från varandra så är det 8 flyttalsoperationer. Detta helt oberoende av övriga kärnans exekverignsenheter.
Visst är det helt oberoende, men som alla vet finns inga gratis-luncher. Kostnaden AMD betalar för denna design är högre latens än Intels design. I vissa lägen är det inget problem, i andra kommer det orsaka "stalls" i heltalsdelen då den inte kan fortsätta innan resultatet från FPUn är klart. Och då FPUn är delat kan detta mycket väl få effekter på BÅDA trådarna.
Man får inte glömma att de flesta Intel "µops" kräver bara en port och man kan bara avkoda 4 sådana per cykel, så det är totalt 4 instruktioner från 2 olika strömmar som ska samsas om 6 exikveringsportar, så det är inte SÅ osannolikt att man får en riktigt bra match. Har sett uppmätt IPC på Sandy på ~2 i verkliga program, vilket är något högre än vad jag sett på Bulldozer räknat över HELA modulen.
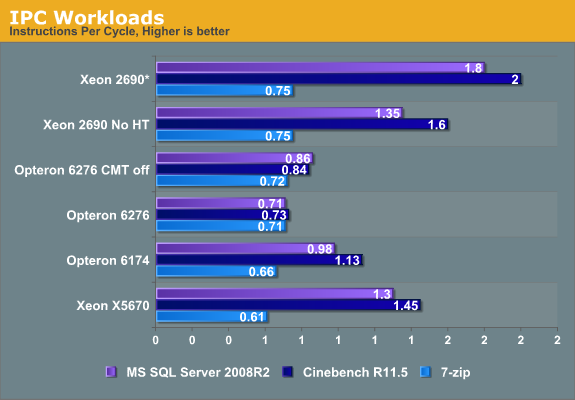
Här är ett sådant exempel, Bulldozer klara totalt sett 0.73*2=1.46 på Cinebench medan Sandy Bridge (Xeon) klara 2.0 (man visar summan av två trådar).
Skrivet av Aleshi:
För att du kan i princip lyfta ut en av AMDs pipes så har du en RISC-processorkärna. Den behöver inte prefetch, och den behöver inte decoder. Den blir ganska primitiv i sin enkelhet. Men det är en CPU.
AMD kör "micro-ops" internt och dessa är "riktiga" RISC instruktioner i att de är fix-längd och endast kan göra load, store eller beräkning. Men Intel har i princip samma sak då de internt kör "µops" som är fix-längd och till största del bara kan göra load,store eller beräkning, man har i vissa lägen valt att kunna göra load-op i samma instruktion då det är VÄLDIGT vanligt i x86 kod. Men resultatet av detta är att den teoretiska kraften hos en Sandy/Ivy-kärna inte alls är speciellt långt i från summan av båda pipes i en modul.
Så diskussionen om det är en "riktigt" kärna är ur det perspektivet meningslös, det enda som räknas är faktiskt prestanda och här har Sandy/Ivy fördelen i att vara mer flexibel då kraften kan alltid används av den tråd som råkar behöva den för tillfället. Vad HT gör är öka genomsnittligt antal exekverade instruktioner då det finns fler val att göra när man ska lägga instruktioner på exikveringsportarna, HT kan också "gömma" latens då den andra tråden kan köra till 100% om den andra måste vänta på en load/store operation. Alla dessa fördelar missar man med separata pipor.
Skrivet av Aleshi:
I en normal dualcore så når man inte perfekt skalning heller. Det kommer alltid bli begränsningar när de ska dela minne, buss, cache och strömutrymme med mera.
Då man i de flesta "desktop" arbetslaster har en total cache-hit-rate i L1/L2 (som både är privat per CPU-kärna på både Nehalem->Ivy och Phenom->Trinity) som ligger över 95% så är det full möjligt att få mer eller mindre perfekt skalning. Med HW-stöd som avancerade NICs och DDIO (Intel's Data Direct I/O en finess i Sandy Bridge baserade Xeon) kan man även få nära nog perfekt skalning i system med flera CPU-sockets och 6-8 CPU-kärnor per socket, vi har det i alla fall i de system vi utvecklar på jobbet. På denna typ av arbetslast är HT mer eller mindre helt värdelöst och har tyvärr inte haft möjlighet att testa hur Bulldozer (Opteron) hanterar detta.
Skrivet av Aleshi:
Jag skulle säga att den är en dålig idé, i alla fall i nuvarande utformning. Den är inte så bra utformad i nuläget, men Steamroller kanske kan ändra på detta. En Bulldozermodul är ju i princip lika stor som två stars kärnor på samma tillverkningsprocess. Inte så konstigt då allt det viktiga finns i dubbel uppsättning och det som delas är uppbiffat. Men jag tror att 8 starskärnor hade presterat bättre än 4 BD-moduler, då AMDs svaghet gentemot intel redan innan var att de inte kunde mata sina exekverinsenheter tillräckligt bra. Det blev inte bättre med den sneda balanseringen i BD. SR löser nog det bra dock.
Frågan är bara vilken marknad AMD vänder sig mot med denna design. Vanliga servers är inte CPU-bundna, utan I/O-bundna, där har man lite nytta av mer kraft för heltasberäkningar. HT fungerar i vissa fall otroligt bra på servers (inte för inte som moderna SPARC och POWER CPUer har 8 resp 4 "HT" per CPU-kärna)
För desktop är hög prestanda per tråd LÅNGT mycket viktigare än många CPU-trådar, i alla fall så fort man har 4 eller fler CPU-trådar totalt sett.
I steamroller kommer AMD även duplicera avkodaren, som för x86 är relativt komplex. Det enda man då "vinner" på att inte köra med "riktiga" kärnor är delad FPU (fast med nackdelen att få hög latens) och delad L1I och L2 cache (frågan hur bra det är då L2 cachen lätt borde bli en flaskhals om den ska mata 2 "riktiga" kärnor).
Så steamroller blir garanterat en förbättring, men det är inte så mycket kvar av den ursprungliga tanken att spara på transistorer genom att dela på saker.
Men anser fortfarande att även dagens modell är helt OK då man ändå uppnår 80% effektivitet på trådarna när båda två i en och samma modul används. Problemet är att prestanda per tråd är alldeles för lågt, DET är vad man måste fixa inte göra ännu fler "kärnor".