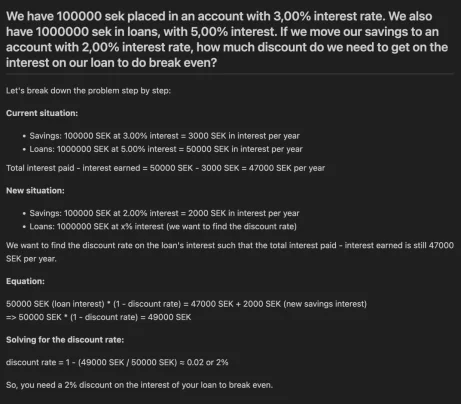
LLama3 eller "Hur kan en språkmodell stapla saker?"
Under förra veckan släppte Meta llama3, en riktigt kompetent LLM som man kan köra lokalt. Går även att köra utan en kraftfull GPU, men var beredd på att varje fråga kan ta lång tid!
Installeras enklast med hjälp av ollama, och sen installeras modellen med
ollama run llama3:8b
eller
ollama run llama3:70b
beroende på hur stor modell man vill ha.
70b tar ungefär en kvart på sig att svara på en fråga på min ganska nya laptop med en i7:a och intel igpu.
Men, det jag egentligen ville prata om är om frågan nedan, där LLama 3 och ChatGPT ger liknande svar. Jag har ganska bra förståelse för hur neurala nätverk, i den mån man nu kan påstå det när forskarna fortfarande debatterar exakt hur de funkar, och lite mindre förståelse för LLM och dess transformationer. Men, hur kan en språkmodell svara på den här typen av frågor? Det känns inte som att det borde finnas tillräckligt många exempel i text för att lära sig utifrån det, eller..?
>>> you have four marbles, a book, a box, a bottle and an egg. How would you place them to build the highest stable tower?
What a fun challenge!
To build the highest stable tower with these items, I'd follow a strategic approach:
1. **Base layer:** Place the box on the ground as the foundation of the tower. It's sturdy and provides a flat
surface.
2. **Middle layer:** Position the book on top of the box. The book is relatively flat and wide, making it an ideal
middle layer that can support the weight above.
3. **Marble layer:** Carefully place three marbles on top of the book, spaced evenly apart to form a triangular
base. This will provide a stable platform for the next layer.
4. **Bottle layer:** Gently place the bottle on top of the marbles, centered and upright. The bottle's narrow
shape allows it to sit securely on the marble triangle.
5. **Egg layer (the crowning glory!):** Finally, carefully balance the egg on top of the bottle. Since the egg is
delicate, it's essential to ensure the tower is stable before adding this final layer.
The resulting tower should look like this:
Box → Book → Marbles (3) → Bottle → Egg
This structure takes advantage of each item's unique characteristics to create a sturdy and balanced tower. The
box provides a solid foundation, the book adds width and stability, the marbles form a triangular base, the bottle
acts as a narrow but stable platform, and the egg rests safely on top.
Please note that building this tower requires patience, gentle movements, and a bit of luck!