Håller med om att rubrikerna för denna och tidigare Intels Downfall-fix sänker prestandan rejält känns lite märkliga, verkligheten är väl ändå precis tvärtom dessa fall.
Benchmark vs mikro-benchmark
Phoronix test-suite är väldigt bra då den innehåller väldigt många tester, är helt fri att använda (och är öppen källkod) samt helt automatiserad.
Problemet med Phoronix test-suite är man måste vara ordentligt påläst för att överhuvudtaget fatta vad som faktiskt testas, har själv i praktiken noll koll på vad >50 % av sakerna de tester egentligen är ett test av. Positiva är att när något sticker ut är det ju bara ladda ner det hela och läsa på vad som faktiskt testas.
I fallet Downfall bör man notera vad som inte testas givet att det som sticker ut är saker som Ospray: Blender finns inte med trots att Ospray och Blender båda handlar om rendering. Orsaken är med väldig stor sannolikhet att prestanda i Blender knappt påverkas.
Fast hur är det möjligt att Ospray påverkas om Blender inte göra det, båda är 3D-rendering?
Ospray testerna som påverkas är uteslutande mikro-benchmarks, de testar ett väldigt specifikt moment i en större pipeline, de testar inte ett fullständigt flöde som att rendera en hel scen i Blender. För Downfall är det väldigt specifika moment som kan påverkas "upp till 50 %", men på ett helt flöde kanske detta moment står för <5 % totala beräkningstiden vilket gör att påverkan i "verkliga" fall ofta blir fraktioner av procentenheter.
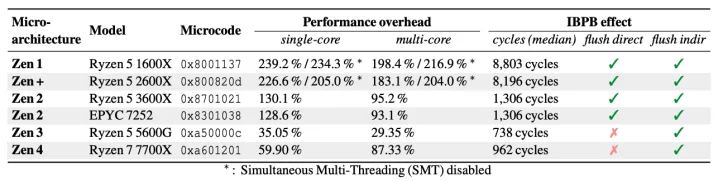
Givet att AMD sa att de förväntade sig att fixarna för Inception inte skulle ge speciellt stor påverkan var jag övertygad om att samma sak gällde detta. Verkar ha haft fel om Inception...
Kritiskt vad och hur information kan läcka
Downfall (påverkar primärt CPU-modeller med AVX-512 stöd innan Alderlake), Zenbleed (påverkar bara Zen2) och DIV0 (påverkar bara Zen/Zen+) som alla presenterats rätt nyligen delar alla egenskapen att de "bara" kan läcka information från program som nyligen kört på samma fysiska CPU-kärna.
Alla dessa delar egenskapen att det är information i SSE/AVX register som kan läcka, men de kan inte läcka godtycklig information. D.v.s. helt klart ett hål, men rätt begränsat vad som är åtkomligt.
Delen jag helt missat i Inception är vad det som kallas "Phantom speculation" faktiskt går ut på. Phantom speculation, som är specifikt för hela Zen-serien, presterades tydligen redan förra året. Det fick nog inte så mycket uppmärksamhet i pressen då Phantom speculation i sig inte är tillräckligt för att orsaka data-läckage.
Men det visade sig kombon Phantom speculation och "Training in Transient Execution (TTE)" i praktiken är motsvarigheten till Meltdown på flera sätt!
Betydligt värre attack-vektor
Inception och Meltdown (som inte bara påverkade Intel utan även vissa POWER och någon enstaka Arm modell) är i grunden helt två separata klasser av sårbarheter, men de delar vad som kan läcka: vilket tyvärr innefattar innehållet i kernel-minne!!!!
De flesta av dessa CPU-sårbarheter är otroligt teoretiska attacker, de är mer att jämföra med "det är en förhöjd risk att ge sig ut i trafiken, men de flesta accepterar den risken då fördelarna överväger". Majoriteten av Spectre-attackerna verkar ens sakna fungerande proof-of-concept.
Inception delar tyvärr även Meltdown-egenskapen att det är, i sammanhanget, relativt enkelt att utnyttja buggen. Är inte fullt lika illa som Meltdown då det verkar ta längre tid att läcka via Inception, men då det som läcker innefattar kernel-minne finns inte alls något krav att köra på samma CPU-kärna som den man vill stjäla information från -> webbläsaren (JavaScript) blir en realistisk attack-vektor.
Alla out-of-order CPUer verkar mottagliga för TTE, det inkluderar Intels. Det är via TTE som data rent tekniskt läcker. Men utan "Phantom speculation" är man beroende av extremt specifika kod-sekvenser (s.k. "gadgets") för att kunna utnyttja detta, i praktiken är det ofta så att "rätt" gadget överhuvudtaget inte finns.
Det Phantom speculation gör är att man som "attacker" i praktiken kan skapa sina egna gadgets, vilket gör TTE användbar...
Givet att AMD känt till denna sedan minst i februari i år är det lite underligt att man inte har skydd mot alla CPU-modeller redan nu. För likt Meltdown är detta nog en sårbarhet man nog ska applicera motmedel mot på en datorn man surfar med.