Backar man 10 år hade vi haft en väldigt lång period med rätt liten ökning i IPC under många år. Något lyckades Apple lura ut rätt snabbt i deras egen design, för de hade redan ett par generationer innan M1 släpptes långt högre ISO-frekvens prestanda jämfört med alla andra, inklusive AMD/Intel.
Både AMD och Intel har ökat storleken på sina CPU-kärnor väldigt mycket vid de senaste generationshoppen, så uppenbarligen har de hittat relevanta saker att stoppa transistorer på för både Zen4 och Golden Cove gav en av de större IPC-ökningar någonsin för respektive tillverkare. Fast de har också ökat effekten rejält, är fortfarande förvånande att plocka upp min Linux-laptop med i7-5600U som faktiskt är nästan helt tyst (det är en 15W TDP x86 CPU som faktiskt sällan drar mer än 15W, det slutade definitivt med 7000/8000-serien någonstans...).
Men givet att inte bara Apple, utan även Arm och snart också Qualcomm har betydligt högre ISO-frekvens prestanda jämfört med x86_64 gängen så kvarstår ändå frågan "varför är det så väldigt stor skillnad givet ungefär samma transistorbudget" (Zen4 och M2s stora kärnor är trots allt rätt snarlika i storlek på samma TSMC 5nm men M2 har 50-60 % högre "IPC").
Så uppenbart möjligt att öka IPC med 40 %. Frågan är bara vad som krävs för att lyckas i form av transistorbudget.
Finns ett par uppenbara skillnader som påverkar "IPC" mellan x86_64 och ARM64, ingen aning om de kan förklara skillnaden vi ser eller om det finns andra viktiga delar.
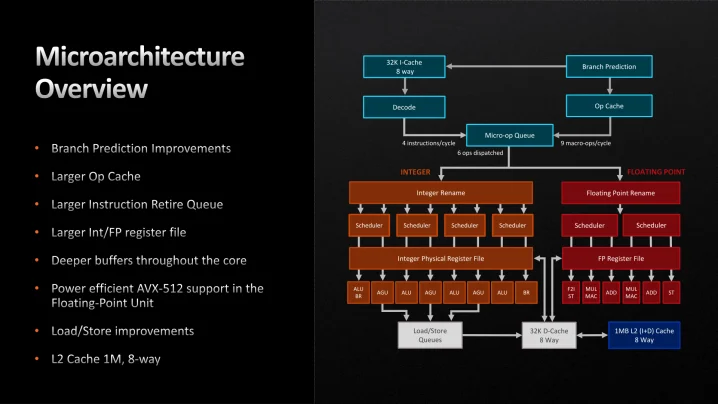
En superviktig sak är flag-register, det är i praktiken som att skriva multitrådade program där alla trådar har en delad variabel som de väldigt frekvent måste läsa/skriva (dödar parallellism ordentligt). ARM64 har ett flagregister, men tillskillnad från x86 påverkar de flesta instruktioner inte detta (finns speciella varianter av de flesta instruktioner som sätter flaggor, kompilatorer använder dessa väldigt sparsamt). Kommande APX för x86_64 kopierar detta från ARM64.
RISC-V har tagit detta ännu ett steg längre, där har man helt skrotat flag-registeret. Råder delade meningar om hur vettig den idén är, men blir väldigt spännande att följa den utvecklingen nu när det börjar komma lite high-end modeller (bl.a. Tenstorrent är på väg ut med en 8-wide RISC-V CPU).
En annan sak som skiljer x86_64 och ARM64 är att både AMD och Inte förlitar sig rätt mycket på micro-op cache i front-end. Arm kopierade detta för deras högst presterande kärnor under ett par generationer, men de har tagit bort det från Cortex X3. Apple har aldrig använt detta, så gissar att Qualcomm inte heller kommer köra med det givet att han som designat Qualcomms Oryon och designade "Apple Silicon" CPUerna.
Även här har x86_64, ARM64 och RISC-V tagit olika vägar. x86_64 har den totalt vansinniga varianten med dagens mått mätt, instruktioner kan vara allt från 1 byte till 15 bytes. RISC-V har en extension som i praktiken alla implementerar som gör att de vanligaste instruktioner är 2 bytes och de flesta är 4 bytes (något även 32-bit Arm har med Thumb2). Hos ARM64 är alla 4 bytes, vilket gör det enklast för dessa med extremt bred front-end.
AMD/Intel kan bara fylla en väldigt bred backend när saker kommer ur micro-op cache, blir nog för dyrt att ha en x86-frontend som kan avkoda supermånga instruktioner. Cortex X4 front-end som kan avkoda upp till 10 instruktioner per cykel. Exakt hur många M1-3 kan avkoda är till viss del spekulation, det är i alla fall minst 8 men kan vara fler hos M2/3. Zen4 kan max avkoda 4 x86_instruktioner, vid uop-cache hit kan den dock leverera upp till 9 uops.
En sak som jag har för mig AMD redan sagt är att man Zen5 kommer ha en bredare "front-end". Får se vad det ger.
Skrivet av the squonk:
Angående storlek på chips så är Apples M3 faktiskt jättestor trots absolut senaste tillverkningstekniken, Apple ligger alltid en generation före i nod, så hög IPC och stort chip kan förklara dom måttligt höga frekvenserna. Det är alltid en balansgång, tex om Zen 5 faktiskt får 40% bättre IPC men bara klockar till 4.5GHz vs Zen 4 som når 5.7GHz så är det mindre imponerande.
Själva kretsen må vara stor, men majoriteten av den tas upp av GPU (framförallt på Pro/Max).
Jämför man M2 med Zen4, där båda är tillverkade på TSMC 5 nm, så är CPU+L2$ något större för M2. Fast då får man ha med sig att L2$ är 4 MB per kärna hos M2 och tar ~50 % av ytan medan den är 1 MB per kärna hos Zen 4 och tar ~20 % av ytan.
Så själva beräkningsenheterna är mindre i M2 jämfört med Zen4, trots långt högre "IPC" (korrekt "långt högre ISO-frekvensprestanda"). Det inkluderar då ändå L1$ som är 192kB I$ / 128kB D$ hos M2 och 32kB/32kB hos Zen4.