Hmm, när jag hörde om GCD och MCD på RDNA3 så tänkte jag mig något i stil med att MCD:n är minneskontroller och infinity-cache, medan resten är på GCD:n. Kändes som en naturlig väg att gå, givet ändringarna de gjorde i RDNA2. Ni kan tänka er lite som en kopia av Zen2 (med bara en CCX), där minneschipleten även har en stor cache (kanske t.o.m större än RDNA2).
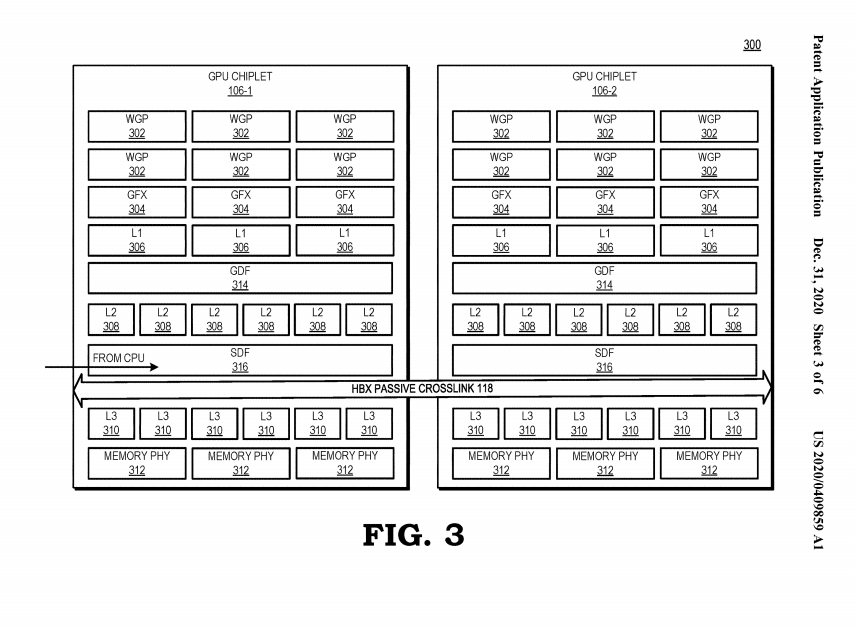
Men som de gjort här har de infinitycachen utspridd över flera chiplets, och det verkar inte finnas någon MCD alls (minneskontrollerna sitter på vardera chiplet enligt figur 3) och alla är egentligen små GPU:er som kommunicerar med varandra. Det positiva med det här är att det är likadana kretsar i en litet grafikkort som i ett stort. Idag är det olika kretsar som tillverkas och designas, t.ex Navi21, Navi22, Navi23, Navi24. Så med den här metoden skulle de möjligtvis bara kunna göra en Navi24 och koppla ihop dem till alla andra. Det lär förhoppningsvis spara en hel del pengar och göra så att lanseringarna hamnar närmare varandra.
Ni kanske kommer ihåg en intervju med David Wang där han säger att det stora problemet är att göra designen osynlig för programmeraren. Den viktigast stycket i patentet är det här:
Accordingly, as discussed herein, a passive die interposer deploys monolithic GPU functionality using a set of interconnected GPU chiplets in a manner that makes the chiplet implementation appear as a traditional monolithic GPU from a programmer model/developer perspective. The scalable data fabric of one GPU chiplet is able to access the lower level cache(s) on other GPU chiplets in nearly the same time as to access the lower level cache on its same chiplet, and thus allows the GPU chiplets to maintain cache coherency without requiring additional inter-chiplet coherency protocols. This low-latency, inter-chiplet cache coherency in turn enables the chiplet-based system to operate as a monolithic GPU from the software developer's perspective, and thus avoids chiplet-specific considerations on the part of a programmer or developer.
Såvitt jag kan se så uppfyller det kraven som Wang ställt för ett grafikkort för spelgrafik.