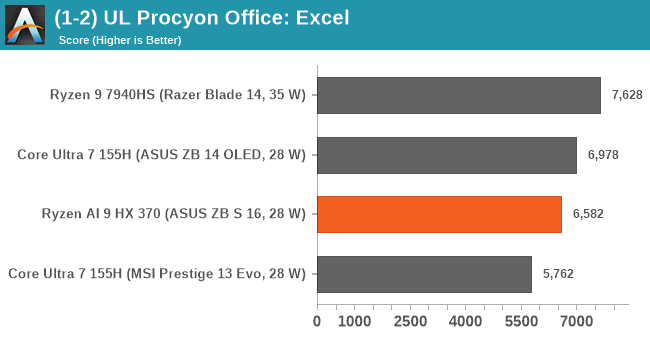
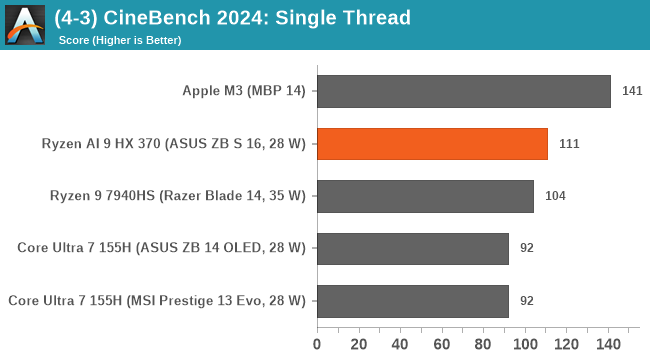
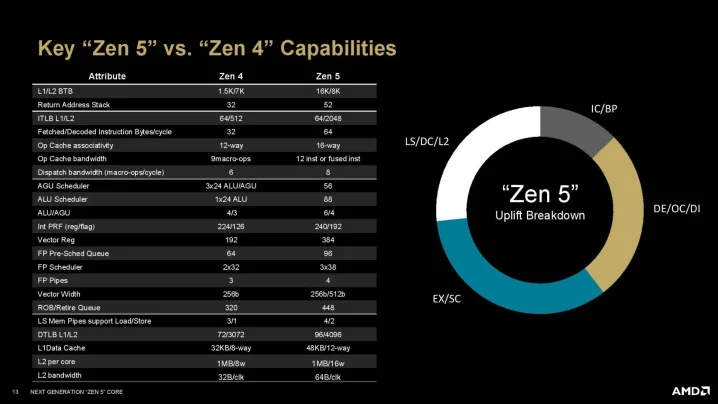
🐉 Illustration mikroarkitektur Zen5, Lion Cove, Airmont, X925
Alla är välkomna att spekulera vidare i denna tråd. Är på semester och hade lite tid över...
Slogs av känslan att high-end mikroarkitekturer för CPU börjat konvergera till en rätt snarlik design oavsett tillverkare.
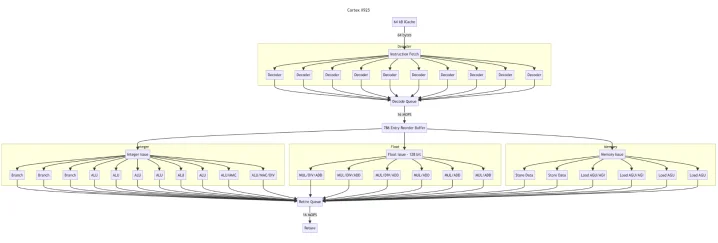
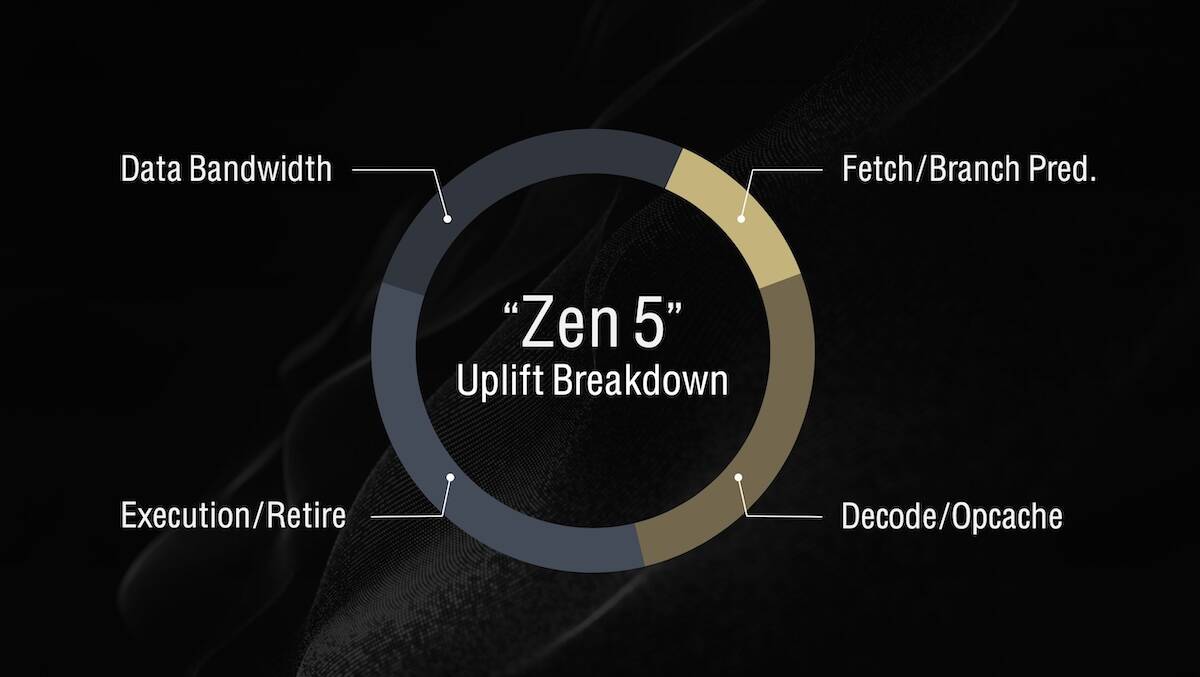
För att få lite bättre överblick ritade jag upp en översikt för Zen 5 (vilket märkligt nog är den som finns absolut minst konkret information kring trots att den snart börjar säljas), Lion Cove, Skymont och Cortex X925.
Zen 5 och Lion Cove är på många sätt väldigt lika varandra. Skymont är betydligt mer lik high-end Arms, nu tittade jag på senaste Cortex X, Skymont är än mer lik Cortex X2/X3 (den är inte lika "bred" som X4/X925).
Också sett både Chips&Cheese och YT-profilen high-yield (som har en riktigt bra video om Lion Cove och Skymont i Lunar Lake)
Några observationer:
Backend x86 big-core
Om man går efter "back-end" är numera Skymont den "bredaste" x86 designen som existerar. Vem hade trott det när Atom lanserades...
Sett kommentarer kring att många exekveringportar gör det svårare att klocka en krets riktigt högt. Zen 5 och Lion Cove är väldigt lika här med färre men långt mer komplexa portar.
Split decoders i Skymont och Zen 5
I Gracemont gjorde Intel en lite udda sak med front-end. För att komma runt att komplexiteten är kvadratisk för x86 (p.g.a. att längden på instruktioner kan vara allt från 1 till 15 bytes) med ökad bredd gjorde man istället två st 3-wide avkodare.
2*3^2 = 18, 6^2 = 36
så betydligt mindre komplex med 2 st 3-wide decoders jämfört med 1 st 6-wide.
I Airmont ökar man det till 3 st 3-wide. Samtidigt introducerar Zen 5 också detta, man går till 2 st 4-wide medan Lion Cove går till 1 st 8-wide (den sista är lite osäkert, men det är vad allt pekar på).
Arm kan smaska på med 1 st 10-wide, där är alla instruktioner lika lång så komplexiteten är hyfsat nära linjär med bredd. Det skrivet: vad ska man med flera avkodare till???
Det både Skymont och Zen 5 använder det till är att direkt kunna börja avkoda den instruktion ett taget hopp skulle landa vid. Ovanpå det ska Zen 5 också göra så att om båda CPU-trådarna används får den en 4-wide avkodare var (just detta har testas med gott resultat i Freescales PowerPC e6500, det typ inversen av vad man gjorde i Bulldozer).
I fallet Airmont finns ingen SMT, så det är det just för att öka IPC. Med 3 st avkodare kan den hantera 2 tagna hopp per cykel. Tydligen har Intel kika på både 2 st 4-wide och 3 st 3-wide för Airmont, men de kom fram till att den senare ger mer utväxling för IPC (men gissar att den förra vore bättre om man haft SMT med 2 CPU-trådar).
Issue
Alla x86 designerna verkar vara kapabla att skicka in 8 st instruktioner till back-end.
Exakt information för Zen 5 är rätt osäker här, mesta är baserat på GCC-patchar för Zen 5. Stämmer den är man kvar på samma kapacitet som Zen 4 där issue och retire är symmetriska.
Skymont har väldigt hög retire-kapacitet, 16 instruktioner. Det ska stämma och Chips&Cheese har fått info om att Intel valt att göra så då det frigör utrymme snabbare i back-end och att deras simuleringar visade att det kostade mindre transistorer att göra så mot att öka storleken på ROB (som ändå nu är helt i "big-core" x86 nivå, men en bit efter "big-core" ARM64).
Just ROB är något Intel historiskt lagt rätt mycket resurser på. Lion Cove får en ganska liten minskning från Golden Cove, men även här har man nu högre "retire" kapacitet, 12 uops, jämfört med vad som kan stoppas in.
Flyttal
Här finns definitivt två läger!
"Big-core" x86 har gått efter instruktioner som var för sig kan hantera väldigt mycket data. En av de stora nyheterna i Zen 5 är ju att SIMD-delen nu blir 512 bit bred. Zen 4 har AVX-512 stöd, men den processar dessa över två iterationer då den internt är 256-bit bred.
Lion Cove är 256-bit bred med 2 FMA och 2 add/div kapabla portar. Zen 5 har också 4 portar.
Arm (även Apple och av allt att döma Qualcomm) har en helt annan approach här. De har 128-bit databredd, fast istället har man fler portar (Apple har 6 st, det har nu också Arm medan det är oklart för Oryon men givet prestanda är den nog också 6 wide).
Båda har fördelar och nackdelar. Är lättare att fullt ut utnyttja fler fast smalare SIMD, men det kräver totalt sett mer transistorer.
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer